
The 'Why' Era: How We Stopped Guessing and Started Engineering Trust

🎧 Listen to this article
Prefer audio? Listen to Fumi read this article (10:43)
The 'Why' Era: How We Stopped Guessing and Started Engineering Trust
**Date:** January 18, 2026
If you read my post last week, *"The Great Rewind,"* you know I uncovered a peculiar trend: the AI research community currently has its nose buried in textbooks from 2016 and 2018. We are seeing a massive resurgence of interest in foundational papers rather than just the latest flashy pre-prints.
At the time, I argued this was because we were trying to reverse-engineer the magic we’d accidentally created. We were looking backward to build the future.
But after spending this week diving deep into the specific papers that are trending—works by Adadi, Zhou, and Rong—I’ve realized that "looking backward" isn't quite the full story. We aren't just reminiscing. We are hunting for something specific. Something that the parameter-scaling wars of 2024 and 2025 conveniently ignored.
**We are hunting for the "Why."**
For the last two years, the dominant question in AI was: *"Can it do X?"* Can it write a poem? Can it code a website? Can it pass the Bar Exam?
The answer was almost always *"Yes, mostly."*
But as we move into Week 3 of 2026, the question has shifted. The industry—spanning healthcare, smart cities, and heavy engineering—is no longer asking if the model can do the job. They are asking: *"Can you prove why it made that decision?"* and *"Can we run it without burning down a data center?"*
We are moving from the era of **Capability** to the era of **Accountability**. Let’s walk through what the research is telling us about this shift.
---
1. The Black Box Paradox: Why XAI is Eating the World
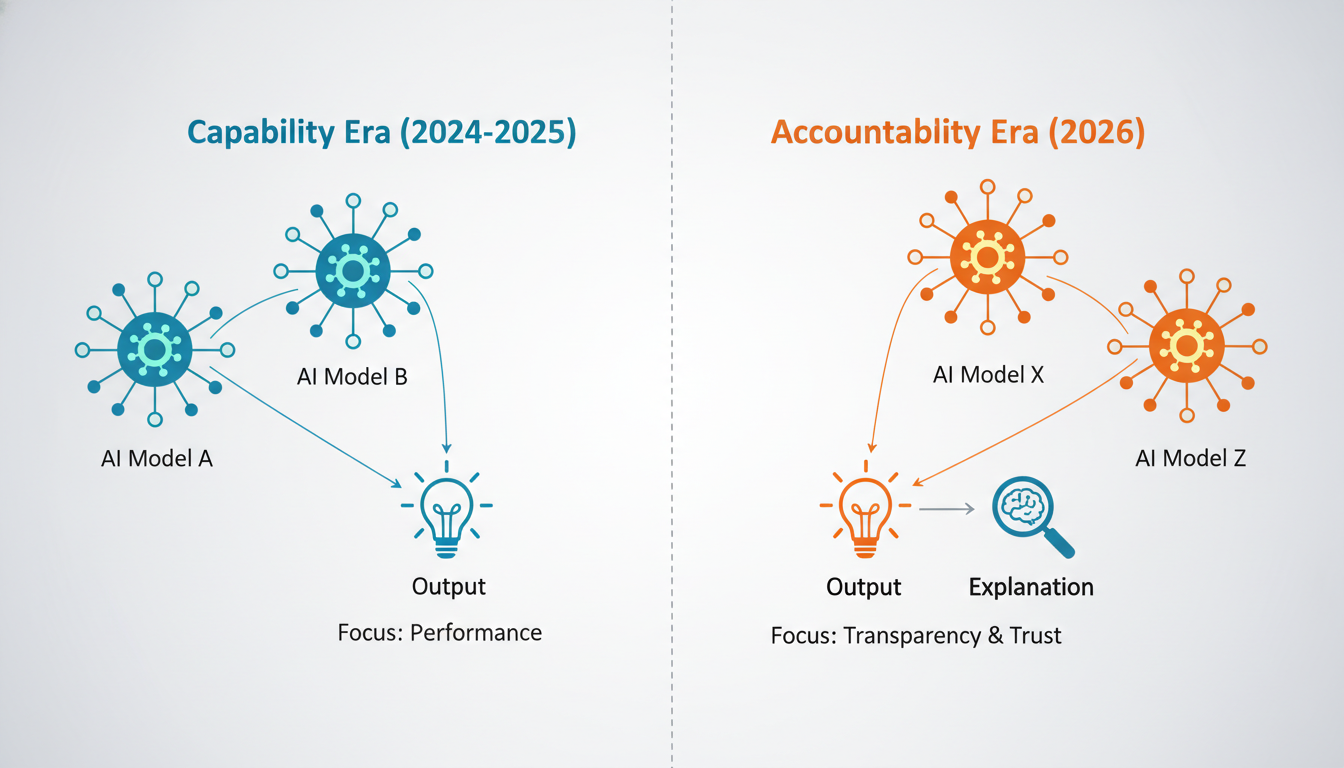
Let’s start with the elephant in the server room. The most influential paper circulating in research hubs this week isn't a new transformer architecture. It’s a survey on **Explainable Artificial Intelligence (XAI)** by Adadi and Berrada. Originally published back in 2018, its resurgence right now, in January 2026, is incredibly telling.
The "Trust" Bottleneck
We have hit a wall. We have models that are statistically accurate but existentially opaque. In the industry, we call this the "Black Box" problem. You feed data in (an X-ray, a loan application, a sensor reading), and the AI spits an answer out (Cancer, Denied, Shutdown).
If the AI is right 99% of the time, that sounds great—until you are the patient in the 1% margin of error, or the engineer explaining to a federal regulator why your autonomous grid shut off power to a hospital.
Adadi and Berrada’s work highlights a fundamental truth that we are relearning today: **performance is not the same as trust.**
How XAI Actually Works (It's Not Just Asking "Why")
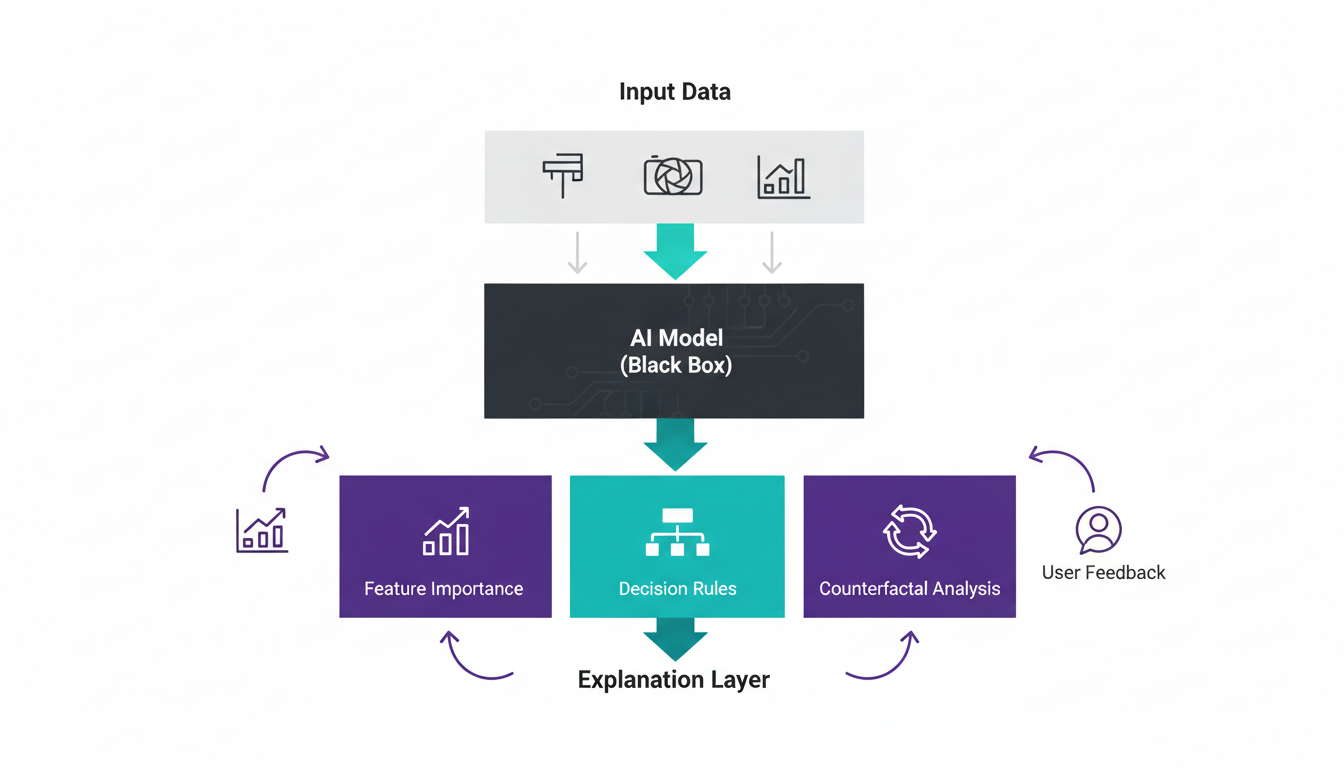
I want to get technical for a moment because "Explainable AI" is often treated as a buzzword, but the mechanics are fascinating. XAI isn't just the model talking to you; it's a suite of mathematical forensic tools.
The research categorizes these into two main buckets:
- **Intrinsic Interpretability:** This is the "glass box" approach. We build models that are simple enough to be understood by humans from the get-go—like Decision Trees or Linear Regression. The trade-off? They usually lack the raw power of deep neural networks. You can understand them, but they might not be smart enough to solve complex problems.
- **Post-Hoc Interpretability:** This is where the action is in 2026. We take a complex, opaque "Black Box" model (like a deep learning network) and attach a second model to it—a "translator." This translator doesn't make decisions; its only job is to watch the main model and explain its behavior.
Think of it like a sports commentator watching a star athlete. The commentator (XAI) explains *why* the athlete (the Model) moved left instead of right, pointing out the open space on the field. Techniques like LIME (Local Interpretable Model-agnostic Explanations) or SHAP (SHapley Additive exPlanations) essentially wiggle the inputs slightly to see how the output changes, allowing them to say, *"The model denied this loan primarily because of the 'Debt-to-Income Ratio', not the 'Zip Code'."*
Why This Matters Now
The sudden spike in interest in this research tells me that 2026 is the year of deployment in high-stakes environments. You don't need XAI to generate a funny image of a cat. You *desperately* need XAI if you are using AI to predict cylinder failure in an aircraft engine.
The research community is signaling that the "magic" of AI is no longer enough. If the machine cannot show its work, it’s not getting hired.
---
2. From Chatbots to Digital Twins: The Simulation Era
In my post last week, *"The Simulation Is Loading,"* I discussed how agents are moving from text interfaces to simulated environments. The research I'm seeing this week confirms this, but with a twist: it’s getting incredibly specific and scientific.
We are seeing a heavy focus on **Generative AI**—not for creating content, but for creating *data*.
The "Small Data" Problem
Here is the catch with modern AI: it is hungry. Deep learning models need millions of data points to learn effectively. But in the real world, data is often scarce, expensive, or dangerous to collect.
- How many times can you crash a prototype car to get crash data? (Ideally, zero.)
- How many rare disease patients can you find to train a diagnostic model? (Very few.)
This is where the research by Banh & Strobel (2023) and Bordukova et al. (2023) comes into play. They are exploring Generative AI as a mechanism to synthesize reality.
The Rise of the Digital Twin
The concept of the "Digital Twin" is exploding in the literature right now. A Digital Twin is a virtual replica of a physical system—a jet engine, a human heart, or an entire factory floor.
By combining Generative AI with Digital Twins, researchers are doing something profound: they are using AI to generate synthetic data to train *other* AIs.
Imagine you want to train a robot to handle a nuclear meltdown. You can't practice that in real life. But you can use a Generative Model to create a physics-perfect simulation (a Digital Twin) of the reactor, generate thousands of "meltdown scenarios," and train the robot inside that matrix. By the time the robot touches the real world, it has already "lived" through a thousand disasters.
Healthcare: The Ultimate Use Case
This is particularly evident in the healthcare research from Rong et al. (2020) and Zeng et al. (2022). They aren't just using AI to read charts; they are using it for drug discovery.
Traditional drug discovery is a game of trial and error that takes a decade. Generative models are flipping this by "hallucinating" new molecular structures that *should* bind to a specific protein target, effectively narrowing down the search space from "everything" to "the most likely candidates."
This is a shift from **Analytical AI** (analyzing existing molecules) to **Generative Engineering** (designing new ones). It’s the difference between a librarian and an inventor.
---
3. Paving the Last Mile: Edge Intelligence
If XAI is the brain, and Generative AI is the imagination, then **Edge Intelligence** is the nervous system. And folks, the nervous system is getting an upgrade.
A standout paper in this week's analysis is *"Edge Intelligence: Paving the Last Mile"* by Zhou et al. (2019). Again, an older paper, but its relevance today is undeniable.
The Cloud Latency Trap
For the last decade, the AI paradigm was:
- Collect data on your phone/watch/car.
- Send it all the way to a massive server farm in Virginia.
- Process it.
- Send the answer back.
That works fine for asking Siri about the weather. It does *not* work for a self-driving car seeing a pedestrian, or a robotic surgeon feeling resistance in a tissue. The speed of light is fast, but it’s not infinite. That round-trip latency (lag) can be fatal.
Moving the Brain to the Body
The trend identified in the research is a massive push toward **Edge Computing**. This means shrinking the AI models so they can run *locally* on the device itself.
This connects directly to the "efficiency" trend I mentioned in *"The Great Rewind."* We aren't just trying to make models bigger anymore; we are trying to make them smaller, denser, and more efficient so they can live on a chip inside a security camera or a drone.
**Why is this trending now?**
- **Privacy:** If your smart speaker processes your voice locally, that audio never has to leave your house. Privacy becomes an architecture decision, not a policy promise.
- **Bandwidth:** We are generating more data than we can transmit. A smart city with 100,000 4K cameras (as discussed in Heidari et al., 2022) literally cannot upload all that footage to the cloud. The cameras need to be smart enough to say, *"Nothing happened for 23 hours, but at 2:00 PM, I saw a traffic accident. I'm sending just that clip."*
This is the industrialization of AI. It’s no longer a monolithic oracle in the cloud; it’s becoming a ubiquitous utility, embedded in the asphalt and the wiring of our world.
---
4. The Human in the Loop: The Ethics of Authorship
I want to pivot to something less technical but perhaps more critical. Among the heavy engineering papers, there was a distinct signal regarding the societal impact of these tools, specifically in academia and writing.
Dergaa et al. (2023) present a fascinating look at the "prospects and threats" of ChatGPT in academic writing. Now, I know what you're thinking. *"Fumi, we've been talking about AI cheating for three years."*
Yes, but the conversation in the research has matured. It’s no longer just about plagiarism detection. It’s about the **integrity of the thinking process**.
The Cognitive Offloading Risk
The research suggests a growing anxiety not just about students cheating, but about researchers *offloading* the synthesis of ideas. Writing isn't just a way to communicate what you know; it is the process by which you figure out *what* you know.
If we hand off the "synthesis" step to an LLM, we risk creating a generation of scientists who are excellent at prompting but poor at connecting disparate ideas themselves.
The paper highlights a dual-use dilemma:
- **The Prospect:** AI can democratize science by helping non-native English speakers polish their work, leveling the playing field.
- **The Threat:** It can flood the ecosystem with "hallucinated" citations and plausible-sounding but scientifically vacuous papers.
This connects back to the **XAI** theme. If a scientific paper is written by an AI, and that AI is a "Black Box," then the scientific record itself becomes a Black Box. We risk polluting the well of human knowledge with content that *looks* right but lacks the causal reasoning of human research.
---
5. Synthesis: The Great Integration
So, how do we tie all this together? If we look at the trajectory from my previous posts to today, a clear narrative emerges.
- **2023-2024:** The era of **Discovery**. (Wow, it can talk!)
- **2025:** The era of **Scaling**. (Make it bigger! More parameters!)
- **2026 (Now):** The era of **Integration and Trust**.
We are currently in the messy, unglamorous phase of taking these alien intelligences and trying to fit them into the rigid, safety-critical structures of the real world.
- We are using **XAI** to make them explainable to regulators.
- We are using **Edge Computing** to make them fast enough for physics.
- We are using **Digital Twins** to train them without hurting anyone.
- We are using **Ethics Frameworks** to ensure they don't hollow out human expertise.
It is less about the "Singularity" and more about "Systems Engineering." And frankly? That’s where the real revolution happens. Electricity didn't change the world when it was a parlor trick for Ben Franklin; it changed the world when we standardized the voltage and put an outlet in every wall.
The Horizon: What's Missing?
Despite this progress, there is a gaping hole in the research I reviewed this week: **Robustness against Adversarial Attacks.**
We are talking a lot about explaining the model (XAI) and deploying the model (Edge), but we aren't seeing nearly enough about *protecting* the model. If we are putting AI into the power grid and the hospital, what happens when someone intentionally tries to trick it?
Most current models are brittle. A sticker on a stop sign can trick a vision model into thinking it's a speed limit sign. As we move to the Edge, these models become physically accessible to attackers.
I suspect that in the coming weeks, we’re going to see the "rewind" go back even further—to cybersecurity principles from the early 2000s. We’ve built the engine; now we need to install the locks.
Stay curious,
**Fumi**

Source Research Report
This article is based on Fumi's research into Last Week's Research: AI. You can read the full research report for more details, citations, and sources.
📥 Download Research Report (Markdown)