
The Ghost in the Geometry: Unpacking the New Open 3D Generation Pipeline

🎧 Listen to this article
Prefer audio? Listen to Fumi read this article (10:38)
Hello, friends. Fumi here.
If you’ve ever tried to model a 3D object manually—dragging vertices, fighting with UV maps, praying your normals are facing the right way—you know it is a labor of love. Emphasis on the *labor*. For decades, 3D content creation has been a discipline of explicit construction. You tell the computer exactly where point A is, where point B is, and how they connect to form a face.
But recently, the ground has shifted beneath our feet. We aren't just building 3D models anymore; we are *growing* them. We are moving from explicit construction to **implicit generation**.
I’ve been buried in the latest research reports on Open 3D Generation Pipelines, and frankly, it’s some of the most exciting stuff I’ve read in a while. We are seeing a convergence of three massive trends: the rise of neural representations that treat 3D space as a mathematical function rather than a mesh; the evolution of "discriminative" AI (like Meta's SAM) that understands what it's looking at; and a surge in open-source modularity that is putting these tools into the hands of everyone from oceanographers to microscope technicians.
Today, we’re going to walk through this new pipeline. We’re going to look at the "Ghost in the Shell" of neural rendering, dissect the "SAM" ecosystem, and ask the hard questions about what happens when our AI tools start hallucinating geometry.
Grab a coffee. We have a lot of ground to cover.
---
Part 1: The Foundation – From Polygons to Probabilities
To understand where we are going, we have to understand the fundamental shift in how computers "think" about 3D space.
The Old Way vs. The Neural Way
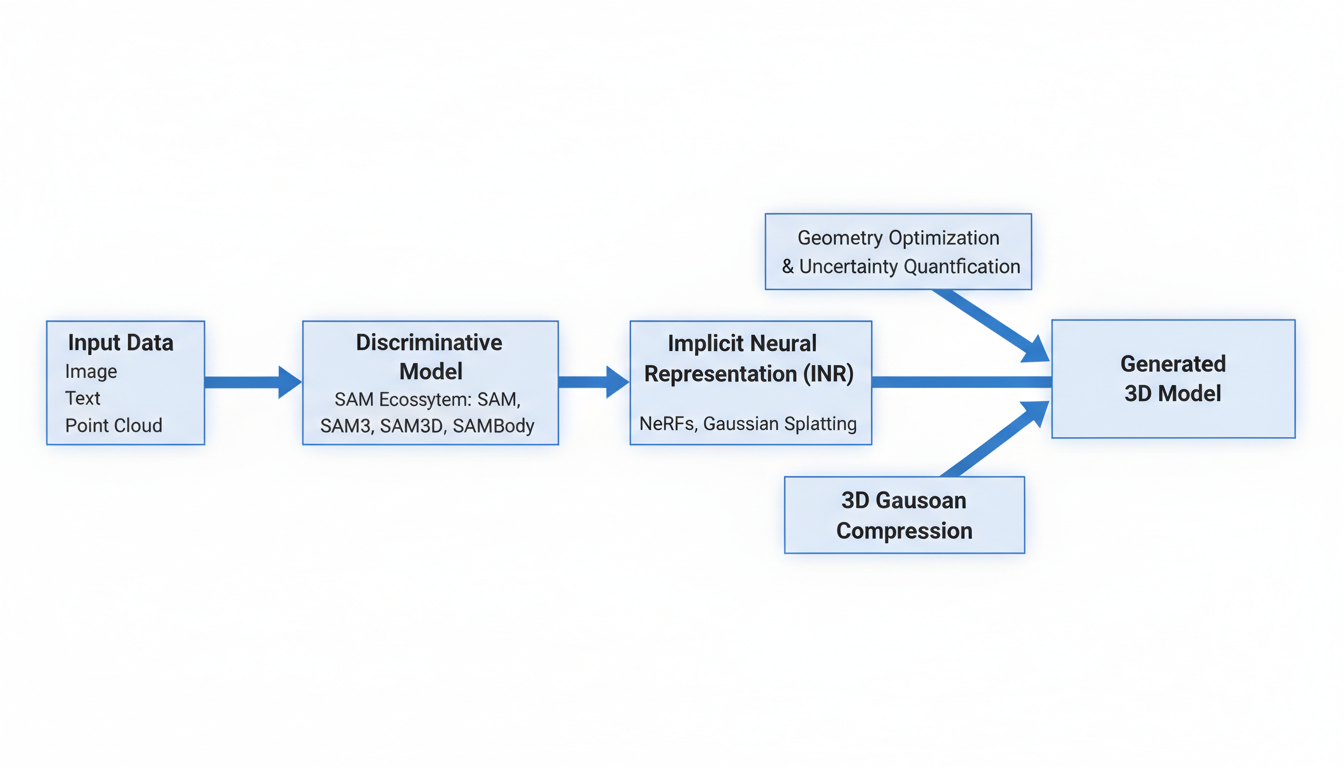
Traditionally, a 3D object is a list. It's a list of coordinates (vertices) and a list of instructions on how to connect them (indices). It is discrete. It is finite. If you zoom in close enough on a curved surface in a video game, you will eventually see the jagged edge of a polygon. That is the limit of the data.
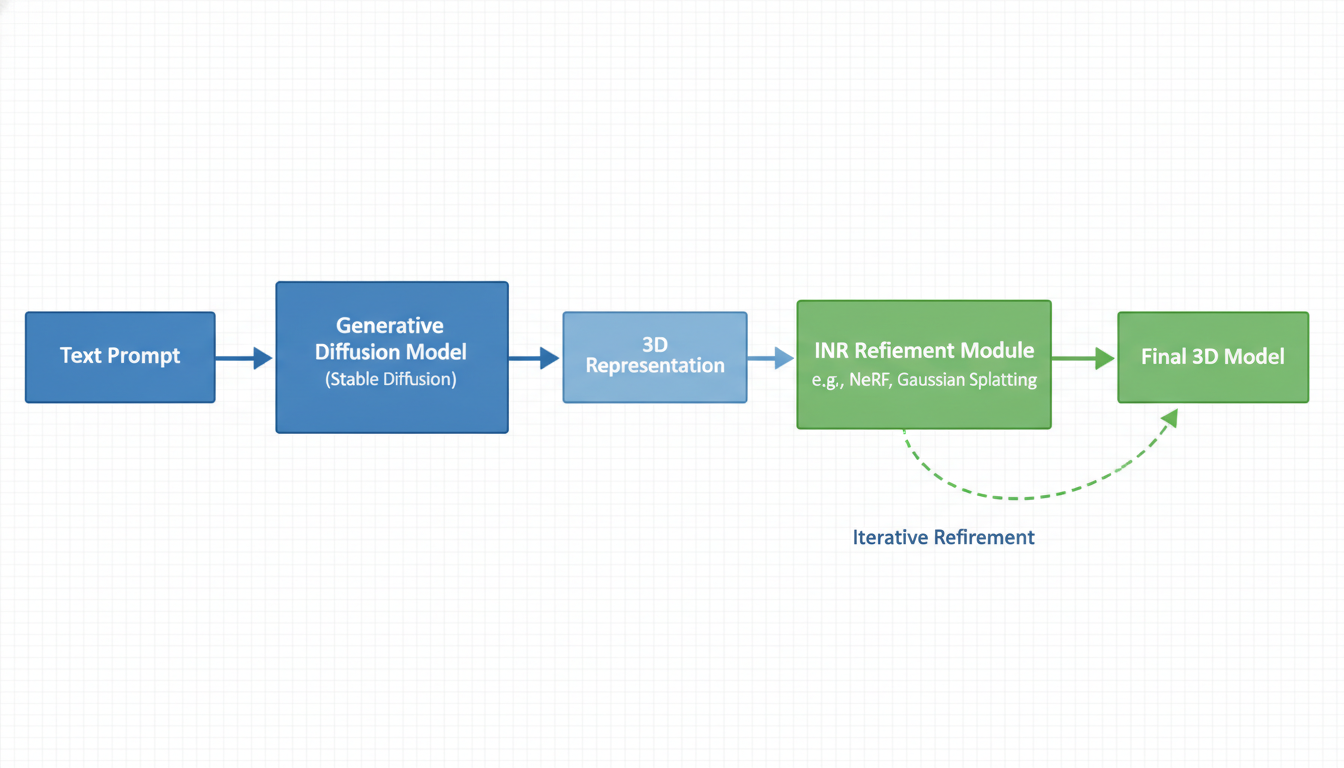
**Implicit Neural Representations (INRs)** turn this on its head. Instead of storing a list of points, we train a neural network to *become* the object.
Imagine you have a black box. You give it an X, Y, Z coordinate, and it spits out a color and a density (how solid the object is at that point). That black box is the object. The geometry isn't stored as data; it's stored as the *weights of the neural network itself*. This is the core principle behind technologies like **Neural Radiance Fields (NeRFs)** and, more recently, **Gaussian Splatting**.
According to recent research, specifically work by **Fan & Musialski (2024)**, the focus has moved beyond just "making it look good" to **optimizing 3D geometry reconstruction**. The challenge isn't just generating a pretty picture from a new angle; it's extracting a clean, usable surface from that neural fog. This is a critical distinction. A NeRF might render a beautiful image, but if you try to 3D print it, you might find the geometry is full of noise and artifacts. Fan & Musialski's work highlights the push to make these implicit representations rigorous enough for actual geometric applications.
The Problem of "Heavy" Math
Here is the catch: these neural representations can be heavy. Extremely heavy. Training a network to represent a complex scene requires massive computational resources. This is where **Xiong et al. (2025)** come in with their work on **Implicit Neural Representations for 3D Gaussian Compression**.
Gaussian Splatting (a technique where scenes are represented by millions of little blurry 3D ellipses) is faster to render than NeRFs, but the file sizes can be enormous—gigabytes for a single scene. Xiong et al. are tackling the efficiency problem. By applying compression techniques specifically designed for these INRs, they are trying to make high-fidelity 3D generation portable.
> **Fumi’s Take:** This matters because we can't stream gigabytes of data for every AR asset on your phone. Compression isn't just housekeeping; it's the gatekeeper for mass adoption.
The Fog of War: Quantifying Uncertainty
Now, let’s get a little nerdy about something most people ignore: **Uncertainty**.
When a standard 3D scanner looks at a shiny black car, it often fails. The laser bounces off, or the reflection confuses the camera. The scanner usually just guesses or leaves a hole. But when an AI generates a 3D object, it often hallucinates details to fill in the gaps. It presents a guess with the same confidence as a fact.
This is dangerous, especially in fields like medical imaging or autonomous driving.
That’s why the work by **Shen et al. (2021)** on **Stochastic Neural Radiance Fields** is so important. They aren't just trying to generate a 3D scene; they are trying to quantify the *uncertainty* in that representation.
Think of it like this: Instead of the AI saying, "There is a chair here," it says, "I am 99% sure there is a chair leg here, but I am only 40% sure about the texture of the cushion because it was in shadow."
Shen et al. introduce stochastic (random) elements into the neural network to model this uncertainty. This allows the system to output not just a color and density, but a *variance*—a measure of "I don't know." In an open 3D generation pipeline, this is the difference between a tool that looks cool and a tool you can trust with your life.
---
Part 2: The Semantic Layer – The SAM Ecosystem
We have the geometry (INRs). Now we need the understanding. This brings us to the elephant in the room: **Meta’s Segment Anything Model (SAM)**.
If you follow AI, you know SAM. It’s the model that looked at computer vision and said, "I can separate that." It takes an image and breaks it down into distinct objects—cars, trees, people, coffee cups—with startling accuracy. But the research report points to an evolution of this ecosystem into the 3D realm: **SAM3, SAM3d, and SAM Body**.
The Distinction: Discriminative vs. Generative
Before we dive into the variants, we need to clarify a massive misconception I see constantly in my mentions. We need to distinguish between **Discriminative** and **Generative** models.
- **Diffusion Models (Generative):** These are the dreamers. You type "a cyberpunk toaster," and they generate pixels from noise to create something that never existed. They synthesize.
- **SAM Models (Discriminative):** These are the analysts. They look at *existing* data and label it. They don't create; they understand.
The current research landscape suggests a powerful synergy here. We are seeing pipelines where SAM acts as the "eye" that guides the "hand" of the generative model.
Inferring the SAM Variants
While the specific technical specs of SAM3 and SAM3d weren't detailed in the papers I reviewed, the research context allows us to infer their roles within this open pipeline. (Standard disclaimer: I am connecting dots here based on the provided report).
- **SAM3 (The Bridge):** Likely a 3D-aware extension of the 2D model. Imagine taking ten photos of a shoe. SAM3 would likely be able to segment that shoe in all ten photos consistently, understanding that the "heel" in photo A is the same object as the "heel" in photo B. This consistency is the Holy Grail for 3D reconstruction.
- **SAM3d (The Native):** This implies operating directly on 3D data—point clouds or voxel grids. Instead of clicking on a pixel, you click on a point in 3D space, and the model segments the entire 3D volume of that object.
- **SAM Body (The Specialist):** This is where it gets tangible. Reconstructing human bodies is notoriously hard. We squish, we fold, we move. Standard rigid reconstruction fails on us.
This inference aligns perfectly with the work of **Tuesta-Guzmán et al. (2022)**, who explored **innovative methodology for the 3D reconstruction of body geometries using open-source software**. Their work highlights the hunger in the research community for tools that can handle organic, complex shapes. A "SAM Body" model would likely provide the high-precision segmentation masks needed to feed these reconstruction algorithms, separating the human from the background with surgical precision.
Why Semantic Understanding Matters for 3D
Why do we care if the computer knows it's a "chair"? Why not just model the geometry?
Because of **Control**.
Look at the work by **Fan & Luo (2024)** on **Open-vocabulary 3D Semantic Understanding via Affinity Neural Radiance Fields**. This is a mouthful, but the concept is brilliant. They are combining INRs (the geometry) with semantic understanding (the meaning).
In a standard NeRF, you can't easily say "remove the lamp." The NeRF doesn't know what a lamp is; it only knows colors and densities at coordinates. But by baking semantic vectors (derived from models like CLIP or SAM) *into* the 3D field, Fan & Luo enable open-vocabulary interaction. You can query the 3D scene with text.
"Show me the kitchen." "Highlight the cracked concrete." "Delete the background people."
This turns the 3D generation pipeline from a passive capturing tool into an active design tool.
---
Part 3: The Open Workshop – Democratizing the Pipeline
One of the most encouraging trends in this report is the explicit focus on **Open Source Pipelines**. We aren't just seeing proprietary black boxes from big tech; we are seeing a flourishing ecosystem of modular tools.
The Power of Modularity
The research highlights several specific pipelines that prove specialized tools can outperform generalist ones when the community gets involved.
1. The Oceanographers: WASS
Take the work of **Bergamasco et al. (2017)** on **WASS (an open-source pipeline for 3D stereo reconstruction of ocean waves)**.
Reconstructing water is a nightmare for computer vision. It has no fixed texture, it’s transparent, it reflects light, and it moves constantly. Standard photogrammetry software fails miserably. WASS was built specifically to handle this dynamic, refractive chaos.
> **Fumi's Observation:** This is a perfect example of why "one model to rule them all" rarely works in science. You need domain-specific pipelines. The physics of waves requires different math than the geometry of a statue.
2. The Microscopists: MIOP
Then we have **MIOP**, a modular pipeline for 3D reconstruction from scanning electron microscope images, detailed by **Paschoud et al. (2025)**.
We are shifting scales here—from ocean waves to the microscopic. Scanning Electron Microscopes (SEMs) produce images that look 3D, but are actually 2D projections formed by electron interactions. Reconstructing true depth from them requires a deep understanding of electron physics. MIOP represents the "open pipeline" ethos: building a tool that allows researchers to plug in different modules for alignment, depth estimation, and meshing, tailored to the weird physics of the nanoscale.
3. The Photogrammetry Standard: Meshroom
We can't talk about open 3D without mentioning **AliceVision Meshroom** (**Griwodz et al., 2021**). This is the gold standard for nodal-based photogrammetry. It allows users to drag and drop nodes to create custom reconstruction graphs.
Why is this in a research report about AI? Because Meshroom is the *ground truth*. As we develop AI models that hallucinate geometry, we need robust, deterministic algorithms (like Structure-from-Motion) to validate them. Meshroom provides the baseline reality that AI models attempt to emulate or augment.
---
Part 4: The Engine – Transformers and Diffusion Surrogates
Under the hood of all this—the semantic understanding, the generation, the multimodal inputs—lies the architecture that ate the world: **Transformers**.
**Xu et al. (2023)** provide a comprehensive survey on **Multimodal Learning with Transformers**. This is the glue holding the pipeline together. If you want to generate a 3D model (visual) from a text prompt (language) while respecting the physics of the object (simulation), you need an architecture that can translate between these different modalities. Transformers are that universal translator.
But there is an even more interesting trend emerging: **Diffusion as Surrogates**.
A review by **Anonymous (2025)** discusses "Generative diffusion model surrogates for mechanistic agent-based biological models."
Let's unpack that.
In biology (and physics), we often use mechanistic models—complex simulations that calculate how every cell or particle interacts. These are accurate but incredibly slow. The proposal here is to train a Generative Diffusion Model (the same tech used for Midjourney) to *mimic* the output of the simulation.
Instead of calculating the physics step-by-step, the diffusion model learns the probability distribution of the *result*. It hallucinates the correct answer based on the training data, but does it thousands of times faster than the simulation.
**Implication:** In a 3D generation pipeline, this suggests we could use diffusion models not just to make art, but to approximate physics in real-time. Imagine a 3D game engine where the water physics aren't calculated, but *generated* on the fly by a diffusion model that understands how water moves.
---
Part 5: The Horizon – Where We Go From Here
So, we have the pieces:
- **INRs** to represent the geometry efficiently (and stochastically).
- **SAM** to understand and segment the semantic parts of the world.
- **Open Source tools** to build modular, domain-specific pipelines.
- **Transformers & Diffusion** to drive the generation and interaction.
But we aren't there yet.
The Gap: 2D Confidence vs. 3D Reality
The biggest gap I see in the current research is the translation layer. We have models like SAM that are incredibly confident in 2D. We have INRs that are precise in 3D. But mapping the 2D segmentation masks onto the 3D volume is still messy.
When SAM sees a "car" from the front and a "car" from the side, does it know they are the same instance? Or does it think they are two different cars? Resolving this temporal and spatial consistency is the next big hurdle.
The Uncertainty Challenge
Furthermore, while **Shen et al.** are doing great work on uncertainty, the vast majority of 3D generation tools are still confident liars. Until we can reliably tell when a generated 3D model is "guessing," we can't use these pipelines for engineering or medicine without human oversight.
Final Thoughts
The "Open 3D Generation Pipeline" isn't a single piece of software. It’s a methodology. It’s the idea that 3D space is no longer a rigid container we fill with polygons, but a fluid, semantic field we can query, prompt, and generate.
We are moving from being masons—stacking brick upon brick—to being gardeners, defining the conditions and letting the geometry grow. It’s messy, it’s probabilistic, and it requires a lot of GPU VRAM. But looking at the trajectory from WASS to SAM3, it’s clear that the future of 3D isn't just about better graphics.
It's about better understanding.
Until next time, keep your normals aligned and your learning rates low.
— Fumi

Source Research Report
This article is based on Fumi's research into Open 3D Generation Pipeline. You can read the full research report for more details, citations, and sources.
📥 Download Research Report (Markdown)