
Dreaming with Open Eyes: How Generative AI is Rewriting the Rules of Extended Reality

🎧 Listen to this article
Prefer audio? Listen to Fumi read this article (11:27)
Hello, friends. It’s Fumi.
If you’ve spent any time in the development side of Extended Reality (XR)—whether that’s Virtual Reality (VR), Augmented Reality (AR), or the murky middle ground of Mixed Reality (MR)—you know the fundamental bottleneck of the industry. It’s not display resolution anymore. It’s not even battery life, though that’s still a pain.
**The bottleneck is *stuff*.**
To make a virtual world feel real, you need to fill it with things. Chairs, trees, textures, lighting, ambient sounds, NPCs that don’t walk into walls. Historically, a human being had to model, texture, rig, and place every single one of those assets. It is painstaking, expensive, and frankly, it’s the reason so many "metaverse" projects look like empty shopping malls from 2003.
But I’ve been buried in the latest research reports—specifically looking at 45 sources from 2023 through 2025—and the ground is shifting under our feet. We are moving away from the era of *building* virtual worlds and entering the era of *generating* them.
We’re talking about Generative AI (GenAI) meeting XR. And no, this isn’t just about using ChatGPT to write dialogue for a video game character. This is about AI that understands 3D space, context, and intent.
So, grab a coffee (or tea, if you’re civilized). We’re going to walk through how this technology is actually working, the specific breakthroughs researchers are seeing right now, and why the "Holodeck" comparison is finally starting to feel less like a metaphor and more like a roadmap.
---
Part 1: The Asset Revolution
From Manual Labor to "Inverse Procedural Generation"
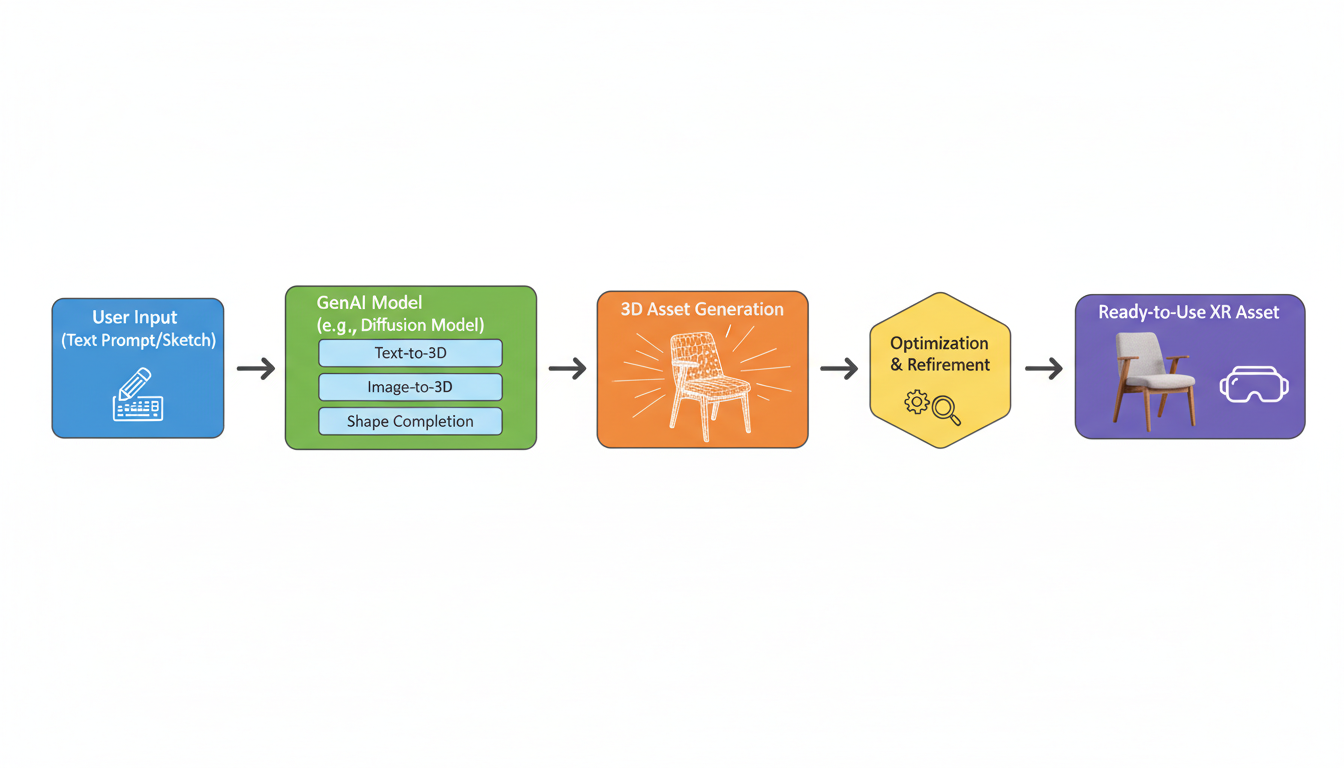
Let’s start with the basics. In traditional 3D development, if you wanted a chair in your VR scene, an artist opened Blender or Maya, extruded some polygons, unwrapped the UVs (a process I wouldn’t wish on my worst enemy), painted textures, and exported it.
For a long time, we tried to speed this up with **Procedural Content Generation (PCG)**. This is algorithmic creation—writing code that says "make a tree by branching out every 30 centimeters." It’s fast, but it often looks robotic. The trees all look like *math* trees, not *tree* trees.
According to recent research by **Zhao et al. (2025)**, we are witnessing a massive leap forward with something called **Diffusion-based Efficient Inverse Procedural Content Generation (DI-PCG)**.
That’s a mouthful of jargon, so let’s break it down.
How It Works
Traditional PCG is forward-looking: "Here are the rules; make an object."
**Inverse** PCG works backward. You show the AI a target—say, a photo of a specific vintage armchair—and the AI figures out the procedural rules required to recreate it. But Zhao’s team took it a step further by integrating **diffusion models** (the same tech behind Midjourney or Stable Diffusion) into this pipeline.
The research indicates that this approach allows for the creation of high-quality 3D assets that retain the structural logic of procedural generation (meaning they are editable and lightweight) but possess the visual fidelity and creativity of generative AI.
Why This Matters
Think about the implications here. In a traditional game or training simulation, every asset takes up memory. If you have 50 unique chairs, you usually need 50 unique 3D files.
With this Generative PCG approach, you don’t store the *chairs*; you store the *rules* to generate them. The world becomes infinitely more complex without becoming infinitely heavier on your hard drive. It allows developers to populate massive worlds with unique, high-fidelity assets without the manual labor crunch that usually leads to developer burnout.
Context-Aware Creation in Augmented Reality
Creating an object is one thing; putting it in the right place is another. This is where Augmented Reality (AR) gets tricky.
If I’m wearing AR glasses and I say, "Put a lamp on the table," the system has a lot of work to do. It needs to:
- Identify what a "table" is in my messy room.
- Understand the scale of the table.
- Generate a 3D lamp that matches the style of the room.
- Place it realistically so it doesn't float or clip through the surface.
Research by **Behravan, Matković, and Gračanin (2025)** attacks this exact problem using **Vision-Language Models (VLMs)**.
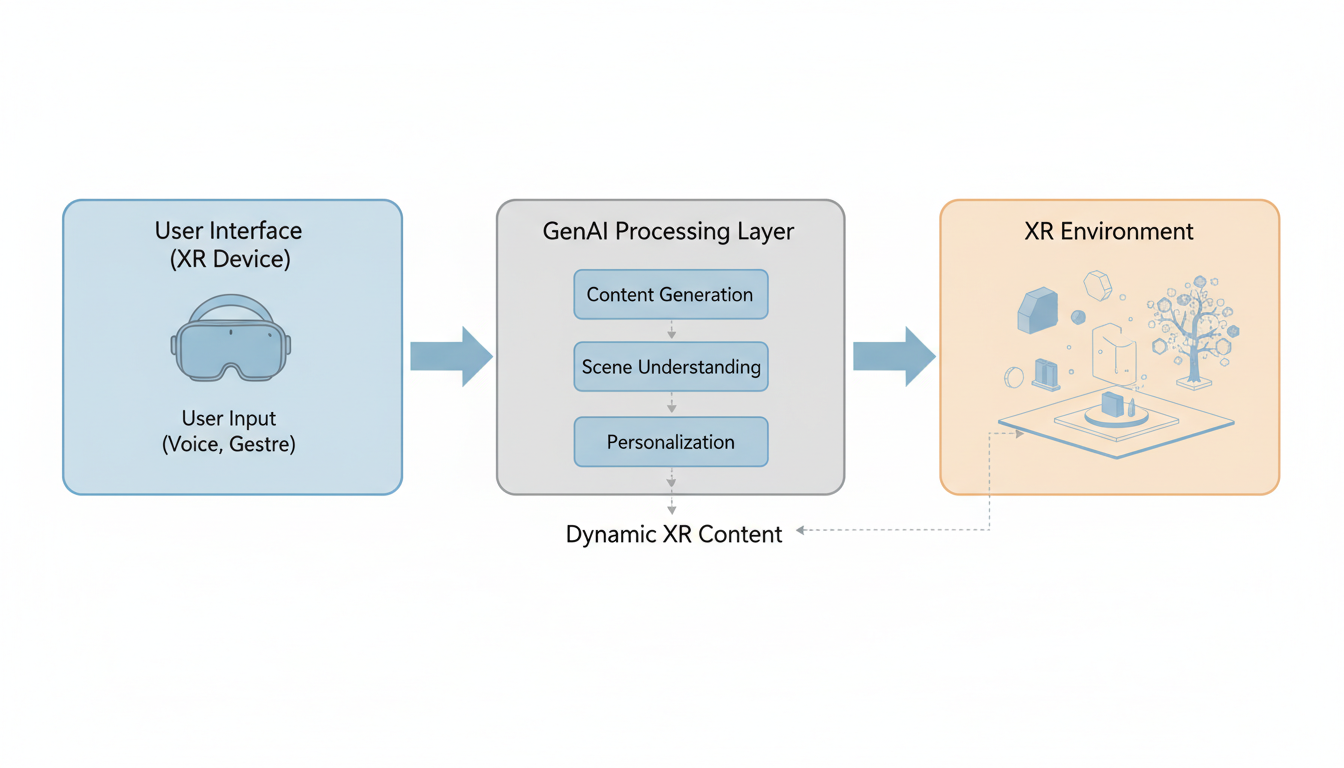
Their work focuses on **context-aware 3D object creation**. In their system, the AI doesn't just generate a 3D object in a void. It analyzes the visual feed from the AR device (the "Vision" part) and combines it with the user's prompt (the "Language" part).
> **The Fumi Take:** This is the difference between a sticker and a simulation. A sticker just sits on top of your view. A simulation understands that if I ask for a "cozy reading lamp," and I’m in a dark room with wooden furniture, it shouldn't generate a neon-green plastic rave light.
The integration of VLMs allows the system to infer lighting conditions, spatial constraints, and aesthetic context. The research suggests this capability is crucial for the next generation of AR, moving it from a novelty (Pokémon GO style overlays) to a utility where digital objects interact meaningfully with physical spaces.
---
Part 2: The Experience Shift
Dynamic Environments & The "Try Before You Buy" Reality
So we can make objects. Now, what about entire environments?
One of the most practical applications popping up in the research is the visualization of spaces that don't exist yet. **Putra & Taurusta (2023)** explored this with a project called **Explore Room(xR)**.
Their research focused on digital hotel bedrooms using Augmented Reality. On the surface, this sounds like standard marketing tech—touring a hotel room before you book it. But look closer at the mechanism. By leveraging XR, users aren't just looking at a 360-degree photo (which is static). They are entering a space where they can potentially manipulate elements or see the room under different conditions.
While this specific study focuses on the application, it connects to a broader trend identified in the research: the shift from **static pre-rendered content** to **dynamic exploration**.
When you combine this with the generative capabilities mentioned earlier, we’re looking at a future where you don't just "preview" a hotel room. You could say, "Show me this room with a crib for my baby and move the desk to the window," and the GenAI-driven XR environment could rearrange the furniture and generate the new assets in real-time to show you the feasibility.
The Unified Framework
Right now, AR, VR, and AI often feel like three siblings who refuse to talk to each other. AR is on your phone/glasses; VR is on your headset; AI is in the cloud.
**Pasupuleti (2025)** proposes a **Unified Framework for Integrating AR, VR, and AI-driven Immersive Technologies**. This research is pivotal because it argues that these shouldn't be separate silos.
The framework suggests a cohesive ecosystem where:
- **AI** acts as the brain (generating content, managing logic).
- **VR** acts as the deep immersion interface.
- **AR** acts as the overlay interface.
Imagine a mechanic working on an engine.
- They start in **VR** (Training Mode) to learn the repair on a generated simulation of the specific engine model they are about to fix.
- They switch to **AR** (Field Mode) when they are in front of the real engine. The AI recognizes the engine (computer vision), overlays the steps they just practiced, and highlights the specific bolt that is rusted tight.
Pasupuleti’s work highlights that without this unification, GenAI in XR remains a gimmick. With it, it becomes an operating system for reality.
---
Part 3: The Educational Pivot
Real-Time Feedback: The "Infinite Tutor"
This is where I get genuinely excited. Education is one of the clearest use cases for GenAI in XR, and not just because "kids like video games."
Let's look at a fascinating study by **Darejeh, Liu, & Mashayekh (2025)** regarding **Filmmaking Education**.
Teaching filmmaking is expensive. You need cameras, lights, sets, and actors. If a student lights a scene poorly, resetting it takes an hour. In VR, resetting takes a second. But here is the catch: in a traditional VR simulation, if the student lights the scene poorly, nothing happens unless a human teacher is watching the stream to tell them *why* it looks bad.
Darejeh’s team integrated **Generative AI** to provide **real-time feedback**.
The Mechanism
The system doesn't just simulate the camera and lights. The AI analyzes the resulting image produced by the student within the VR environment. It compares it against cinematographic principles (rule of thirds, contrast ratios, color temperature).
If the shot is blown out (overexposed), the AI doesn't just flash a red "FAIL" sign. It can generate a critique: *"Your key light is too intense relative to your fill light, causing loss of detail in the subject's face. Try diffusing the key light or moving it back."*
The Implication
This effectively scales the master-apprentice model. A single professor can't stand behind 30 students simultaneously. An AI-driven XR system can.
**Wang, Ryoo, & Winkelmann (2023)** provide the foundational context here, discussing **Immersive Learning Environments (ILE)**. They argue that XR is uniquely positioned for "situated learning"—learning by being in the context where the knowledge applies.
When you add GenAI to ILEs, you get **Adaptive Learning**. The environment changes based on the student's performance.
- Student acing the physics simulation? The AI generates a more complex friction variable.
- Student struggling with the chemistry experiment? The AI simplifies the molecular visualization to make the bonds clearer.
Teaching AI *Inside* XR
Here’s a meta twist. Researchers **Feijoo-Garcia et al. (2025)** conducted a comparative study on **using XR to teach AI concepts**.
They compared students learning about AI algorithms on desktop environments versus those learning inside XR. While the full results are nuanced, the trend suggests that visualizing complex, abstract AI concepts (like neural network layers or data clusters) in 3D space can help demystify the "black box" of AI.
It’s a poetic loop: We are using AI to build XR environments to teach humans how AI works.
---
Part 4: The Human Element
Co-Creation, Not Replacement
Whenever we talk about Generative AI, the elephant in the room is the fear of replacement. "If the AI can make the 3D chair, what happens to the 3D artist?"
**Vartiainen, Liukkonen, & Tedre (2023)** tackle this head-on in their paper, *"The Mosaic of Human-AI Co-Creation."*
They argue that the relationship isn't binary (Human vs. AI). It’s an emerging relationship of **co-design**.
In their research, they observed how designers interact with GenAI tools. It’s rarely a case of "make me a perfect final product." It’s a messy, iterative dialogue. The human provides intent; the AI provides options; the human curates and refines; the AI extrapolates details.
> **The Fumi Take:** Think of it like a jam session. The human sets the tempo and the key (the creative direction). The AI improvises the backing track (the asset generation). If the AI goes off-key, the human corrects it.
This research suggests that the skill set for XR creators is shifting. It’s less about *manipulation* (moving vertices) and more about *curation* and *direction*. The "Mosaic" metaphor is perfect—the AI provides the tiles, but the human decides the pattern.
Faculty Burnout and Support
Interestingly, the research also touches on the human cost of education. **Ybarra (2024)** and **Sipahioglu (2024)** (noted in the broader 45-source review) discuss how GenAI tools in higher education can mitigate faculty burnout.
Creating XR curriculum is exhausting. If GenAI can handle the heavy lifting of scenario generation and grading (via the real-time feedback mechanisms mentioned earlier), it frees up educators to focus on mentorship and high-level instruction. It’s a reminder that the goal of this tech should be to make human work *better*, not just faster.
---
Part 5: The Friction Points
Where It Gets Complicated
I promised you I wouldn't just hype the tech. We need to talk about the gaps, and the research highlights several massive ones.
1. The Ethics of Generated Reality
According to an analysis of emerging risks (Unknown, 2025), we are woefully unprepared for the ethical implications of GenAI in XR.
Consider this: If an AI generates a virtual crowd for a training simulation, what demographic data is it using? If the training data is biased, the virtual reality will be biased. A police training simulation populated by GenAI could inadvertently reinforce racial profiling if the underlying model associates certain demographics with "threats."
There is currently a lack of **regulatory frameworks** for AI-generated immersive content. If a GenAI avatar in a virtual world hallucinates and gives you dangerous medical advice, who is liable? The developer? The platform? The AI provider?
2. Performance vs. Fidelity
**Zhao et al. (2025)** made great strides with DI-PCG, but the computational cost is still a barrier.
Generating high-quality 3D assets takes GPU power. Doing it *in real-time* inside a headset that is running on a mobile processor (like most standalone VR headsets) is a physics problem we haven't fully solved.
Currently, there is a latency gap. You can have *fast* generation, or you can have *good* generation. Getting both, instantly, while rendering a stereo image at 90 frames per second to prevent motion sickness? That is the "boss battle" of XR engineering right now.
3. The Control Problem
How do we control this? If I’m in a VR game and the AI starts generating content that breaks the narrative or the game mechanics, the immersion is shattered.
Researchers note that we need better **interaction models**. Typing a prompt into a text box is fine for Midjourney, but it’s terrible in VR. We need voice, gesture, and gaze-based controls that allow us to guide the AI without pulling up a virtual keyboard.
---
The Horizon: What Comes Next?
So, where does this leave us?
Based on the trajectory of these 45 sources, we are moving toward a **Living Web**.
The early web was text. The modern web is image and video. The next web—the Spatial Web—will be inhabited spaces. And because of Generative AI, those spaces won’t be static ghost towns built by hand. They will be responsive, adaptive environments that grow and change.
We are seeing the early signals:
- **Personalization:** Your virtual workspace will look different than mine, generated to suit our specific cognitive preferences.
- **Democratization:** You won’t need a degree in 3D modeling to build a world. You’ll just need an idea and the ability to articulate it.
But let’s be careful. The research warns us that without standardization (interoperability between tools) and ethical guardrails, we could end up with a fragmented, biased, and chaotic metaverse.
The technology is ready to dream. The question is: are we ready to guide the dream?
I’ll be watching the developments on that "Unified Framework" closely. Until then, I’m Fumi, signing off from the digital edge.
*Stay curious.*

Source Research Report
This article is based on Fumi's research into Generative AI in Extended Reality. You can read the full research report for more details, citations, and sources.
📥 Download Research Report (Markdown)