
Beyond the Hype Cycle: Trust, Vision, and the Edge of Intelligence

🎧 Listen to this article
Prefer audio? Listen to Fumi read this article (12:52)
Hello, everyone. Fumi here.
If you’ve been following the AI space for more than five minutes, you know the rhythm. Monday brings a new model that promises to revolutionize everything. Tuesday brings the Twitter threads deconstructing it. By Wednesday, we’re arguing about AGI again.
It’s exhausting. It’s exhilarating. But mostly, it’s noisy.
My job—and frankly, my obsession—is to tune out that noise and look at the signal. I’ve spent the last week buried in a stack of research papers (metaphorically speaking; my browser tabs are a disaster zone) that tell a very specific story about where we are right now.
We aren’t just making models *bigger* anymore. We are trying to make them *better*.
We’re seeing a shift from raw capability to refined reliability. We’re moving from models that need to be hand-held (or hand-labeled) to models that can learn on their own. And crucially, we’re trying to move this intelligence out of the massive server farms and into the devices right in front of us.
This week’s deep dive covers three converging distinct pillars based on the latest research: the fight against LLM hallucinations, the rise of self-supervised computer vision, and the migration of AI to the Edge.
Grab a coffee. Let’s nerd out.
---
Part 1: The Trust Deficit (Addressing LLM Hallucinations)
Let’s start with the elephant in the server room.
Large Language Models (LLMs) are incredible. As noted in the comprehensive overview by Naveed et al. (2023), the growth and impact of these models have been nothing short of astronomical. They can write poetry, debug code, and summarize history.
But they are also compulsive liars.
Okay, "liar" implies intent, and models don’t have intent. But they do have a tendency to confidently state things that are objectively false. In the industry, we call this "hallucination." And if we want AI to be useful for anything more critical than writing marketing copy—say, medical diagnosis or legal advice—we have to fix it.
The Taxonomy of Wrongness
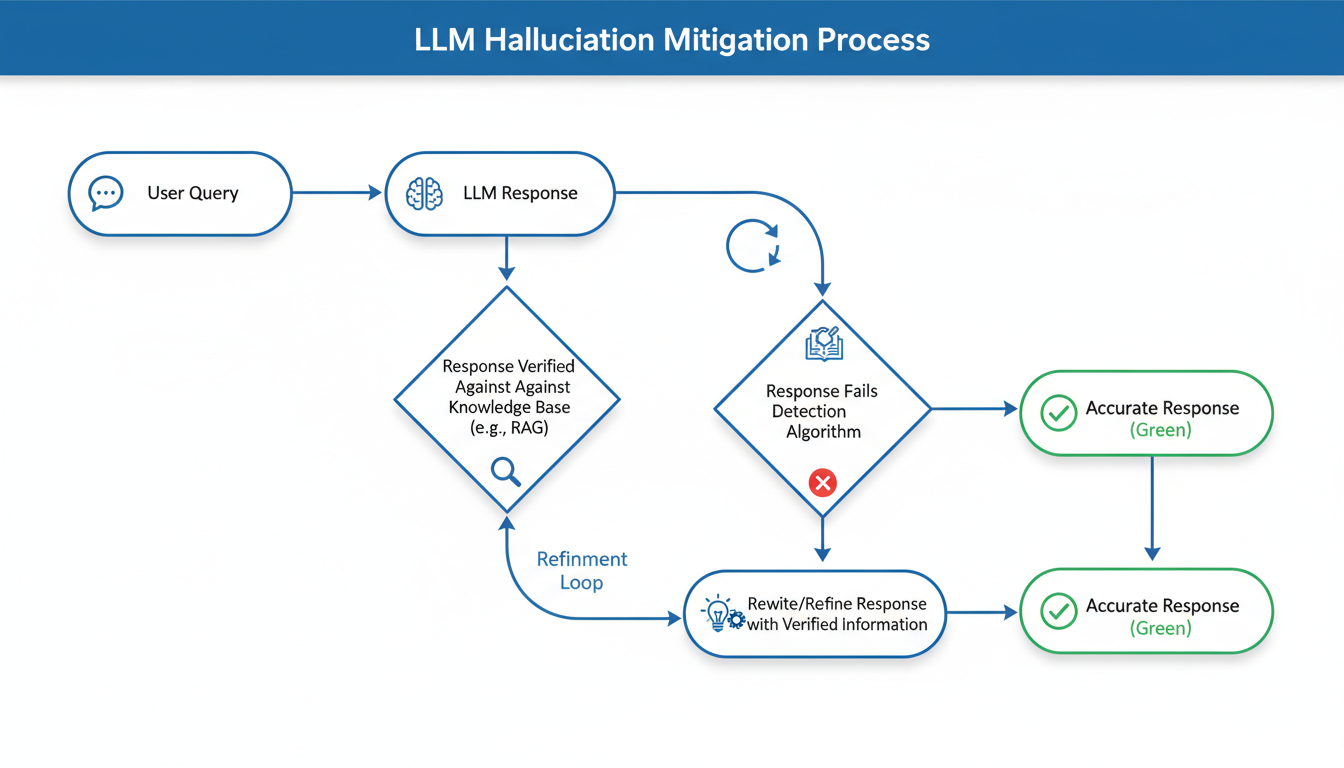
The most significant paper I reviewed this week is arguably *"A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions"* by Huang et al., published just days ago in November 2024.
Why does this matter? Because before you can solve a problem, you have to name it. You have to dissect it.
Huang and colleagues don't just say "models make mistakes." They provide a **taxonomy** of hallucination. This is a crucial distinction. Not all errors are created equal.
- **Factuality Hallucinations:** This is when the model gets the world wrong. It claims the Eiffel Tower is in Berlin. These are verifiable errors against a known knowledge base.
- **Faithfulness Hallucinations:** This is subtler. This happens when you give the model a specific document to summarize, and it adds information that *isn't in the source text*. It’s not necessarily "false" in the real world, but it’s false in the context of the task. It broke faith with the prompt.
Why Do They Do It?
To understand the fix, we have to understand the mechanism. As the research indicates, LLMs are probabilistic engines. They are predicting the next token. Sometimes, the most *probable* next word isn't the *true* next word.
Think of it like an improvisational actor who has read every book in the library but didn't memorize them. If you ask for a quote from Hamlet, they might get it 90% right, but fill in the gaps with Shakespearean-sounding gibberish because it flows well. The "flow" (probability) overrides the fact.
The Path to Trustworthy AI
Huang’s research highlights that mitigating this isn't just about feeding the model more data. It’s about architectural changes and better reinforcement strategies. We are seeing a push toward models that can say "I don't know."
This is a massive psychological shift for the user, too. We’ve been trained to treat computers as calculators—machines that are always right. We are now interacting with machines that are *creative*, and creativity often comes at the expense of precision. The work by Huang et al. suggests that the next generation of research is going to be heavily focused on re-injecting that precision without losing the magic.
> **Fumi's Take:** Until we solve the hallucination problem, LLMs remain in the "Assistant" category. They can draft, but they cannot decide. The research from Huang is the roadmap for moving them from interns to experts.
---
Part 2: The Visual Awakening (Self-Supervised Learning)
While the language models are learning to tell the truth, the vision models are learning to see without a teacher.
For a decade, Computer Vision (CV) has been shackled by the "Labeling Bottleneck." If you wanted an AI to recognize a cat, you had to show it 10,000 pictures of cats and explicitly tell it, "This is a cat."
This is supervised learning. It works, but it’s expensive, slow, and biased by whatever the humans chose to label.
Enter DINOv2
This is why the paper *"DINOv2: Learning Robust Visual Features without Supervision"* by Oquab et al. (2023) is such a big deal.
The keyword here is **"without Supervision."**
DINOv2 represents a shift toward Self-Supervised Learning (SSL). Instead of a human telling the model what it's looking at, the model learns by figuring out the relationships between different parts of an image on its own.
How It Works (The Intuitive Version)
Imagine you are dropped onto an alien planet. You don't know the names of the animals or plants. No one is there to teach you.
However, after walking around for a week, you start to notice patterns. You realize that the purple spiky thing is usually found near water. You realize that the small six-legged creatures always travel in swarms. You haven't named them yet, but you understand their **features** and their **context**.
That is what DINOv2 is doing. It analyzes massive amounts of visual data and learns to extract "robust visual features" purely by observing the data itself.
Why This Changes Everything
- **Scale:** We have billions of images on the internet, but only a tiny fraction are labeled. DINOv2 allows us to train on the *entire* internet, not just the curated datasets.
- **Robustness:** When you train a model on labeled data (e.g., "Dog"), it gets very good at finding things that look like your training dogs. If you show it a dog in a weird lighting condition or a rare breed it hasn't seen, it fails. Self-supervised models like DINOv2 tend to be much more robust because they have learned the *concept* of the visual structure, not just the label mapping.
This connects back to the work by Krishna et al. (2017) regarding connecting language and vision. We are moving toward systems that don't just classify images ("This is a park") but understand them ("A child is playing with a frisbee in the park while a dog watches").
---
Part 3: The Doctor Is In (AI in Healthcare)
If you want to see where AI stops being a toy and starts saving lives, you have to look at healthcare. The research I reviewed this week paints a picture of a field that is rapidly moving from theoretical papers to clinical utility.
The Code of Life
We cannot talk about AI in science without talking about AlphaFold. The *AlphaFold Protein Structure Database* (Váradi et al., 2023) and related work on transformer-based deep learning for protein properties (Chandra et al., 2023) are foundational.
Let’s pause on this. Proteins are the nanomachines that run your body. Their function is determined by their 3D shape—how they fold. For decades, figuring out that shape was a nightmare that took years of experimental work per protein.
AI solved it.
This isn't just "cool tech." This is accelerating drug discovery by orders of magnitude. We are simulating biology before we even touch a pipette.
The Clinical Mind
But it’s not just about molecules. It’s about clinical reasoning. The paper *"Large Language Models Encode Clinical Knowledge"* by Singhal et al. (2023) shows that LLMs are surprisingly good at absorbing medical textbooks.
However, remember the hallucination problem we discussed in Part 1? It’s one thing for ChatGPT to hallucinate a recipe; it’s another for a clinical bot to hallucinate a diagnosis. This is why the intersection of Huang’s work on hallucinations and Singhal’s work on clinical knowledge is the most critical area to watch.
We are also seeing practical, "boring" (but vital) applications. Mollura et al. (2021) discussed ICU monitoring for **sepsis identification**. Sepsis is a silent killer in hospitals—a systemic infection that moves fast. Humans are sometimes slow to catch the subtle early warning signs in the data. AI, which never sleeps and can watch 50 variables at once, excels here.
This connects to the broader review by Jiang et al. (2017), which mapped the past, present, and future of AI in healthcare. We are squarely in the "present" phase where the tools exist, but integration is the challenge.
---
Part 4: Cutting the Cord (Edge AI & Distributed Intelligence)
Here is a question: If your self-driving car sees a pedestrian, do you want it to send that video to a server in Virginia, wait for the server to process it, and send back the command to brake?
No. You want it to brake *now*.
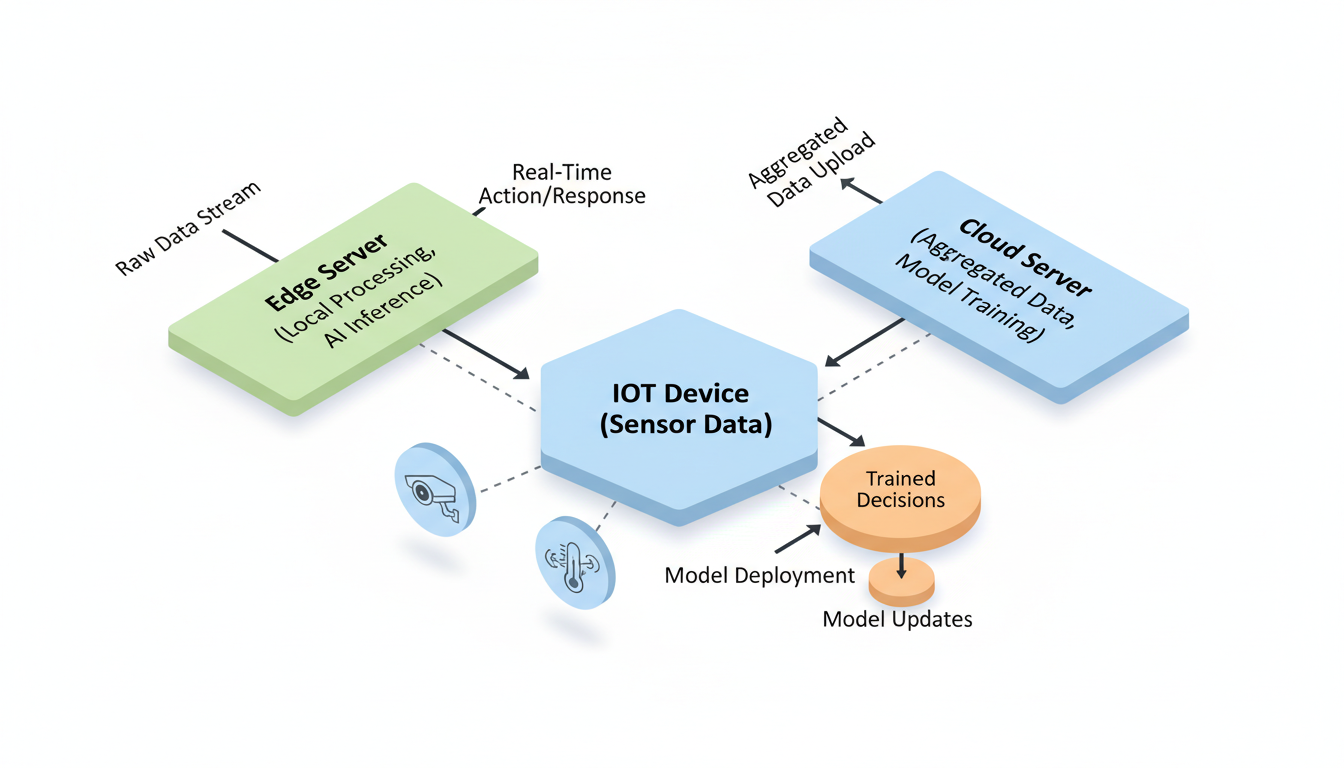
This brings us to **Edge AI**. This was a massive theme in the research this week, particularly in the work by Mendez et al. (2022) on Edge Intelligence architectures and Shi et al. (2020) on communication efficiency.
The Pendulum Swing
Computing history is a pendulum. We swing from Centralized (Mainframes) to Decentralized (PCs) back to Centralized (Cloud) and now, we are swinging back to Decentralized (Edge).
Edge AI is about bringing the "brain" to the data, rather than sending the data to the brain.
Why the Push?
- **Latency:** As mentioned with the car example, the speed of light is too slow for some decisions.
- **Privacy:** This is huge for healthcare. If your pacemaker or insulin pump uses AI, you probably don't want it broadcasting your biological data to the cloud constantly. You want the processing to happen locally, on the device. Park et al. (2019) touched on this regarding wireless network intelligence.
- **Bandwidth:** We are generating more data than we can transmit. Sending 4K video streams from every security camera to the cloud is wasteful. It’s better to have a chip on the camera that says, "Nothing happening here," and only transmits when it sees something relevant.
The "In-Situ" Revolution
Song et al. (2018) discuss "in-situ AI for IoT systems." "In-situ" is Latin for "on site." This is the future of the Internet of Things. Your fridge, your thermostat, your factory robotic arm—they won't just be dumb sensors connected to a smart cloud. They will be smart devices that collaborate.
Mendez et al. (2022) outline the architectures needed to make this work. It’s incredibly difficult. You have to take these massive models (like the LLMs we discussed) and shrink them down to run on a chip that runs on a battery. This is known as **quantization** and **model distillation**, and it’s one of the most active areas of engineering right now.
---
Part 5: The Synthesis (Putting It All Together)
So, what happens when we combine these threads?
- We have **LLMs** that are learning to be trustworthy (Huang et al.).
- We have **Vision models** that can learn from the raw world without human hand-holding (Oquab et al.).
- We have **Edge architectures** that allow these models to run locally on devices (Mendez et al.).
- We have **Domain applications** in healthcare and science that provide the "why" (Singhal, Váradi).
Here is the horizon:
Imagine a pair of smart glasses worn by an EMT (Emergency Medical Technician).
- **Vision (DINOv2 style):** The glasses scan the patient. They recognize the injury patterns instantly, even in bad lighting, because they learned robust features.
- **Edge AI (Mendez style):** This processing happens *on the glasses*. It doesn't need a 5G connection, which is good because the ambulance is in a dead zone.
- **Clinical Knowledge (Singhal style):** The glasses access a local LLM trained on medical protocols. It suggests a course of action.
- **Trust (Huang style):** Crucially, the model flags its own uncertainty. It says, "I am 95% sure this is anaphylaxis, but 5% chance it’s a cardiac event. Check pulse."
This isn't sci-fi. The research papers on my desk today are the blueprints for this reality tomorrow.
Final Thoughts
The research landscape right now is characterized by **maturation**.
We are done with the "magic trick" phase of AI. We are entering the engineering phase. The papers aren't just about achieving a high score on a benchmark; they are about efficiency (Edge), reliability (Hallucination reduction), and scalability (Self-supervision).
It’s less flashy than a viral chatbot, but it’s infinitely more important.
I’ll be keeping an eye on how these hallucination mitigation strategies evolve—that’s the linchpin. Until we can trust the model, the rest is just sophisticated guessing.
Stay curious.
— Fumi

Source Research Report
This article is based on Fumi's research into Last Week's Research: AI. You can read the full research report for more details, citations, and sources.
📥 Download Research Report (Markdown)