
Beyond Generation: Why the Future of AI Might Not Be Generative

🎧 Listen to this article
Prefer audio? Listen to Fumi read this article (12:43)
Beyond Generation: Why the Future of AI Might Not Be Generative
If you’ve spent any time on the internet in the last two years, you’ve likely been drowning in a sea of generated content. We have LLMs writing poetry (of questionable quality), diffusion models dreaming up surrealist landscapes, and chatbots that can roleplay as 17th-century pirates. We call this "Generative AI," and right now, it feels like the only game in town.
But if you look past the hype cycle, past the viral threads and the venture capital frenzies, there is a fascinating counter-movement taking shape in the research labs. It asks a fundamental question that might just change how we build intelligence:
**Is *generating* the world really the best way to *understand* it?**
Think about it. When you watch a glass fall off a table, you don't mentally render every pixel of the shattering glass, the precise refraction of light through the shards, or the exact texture of the spilled water. You predict the *outcome*: the glass will break, there will be a mess, and you’ll probably have to clean it up. You understand the physics and the semantics of the event without needing to generate a high-fidelity video of it in your head.
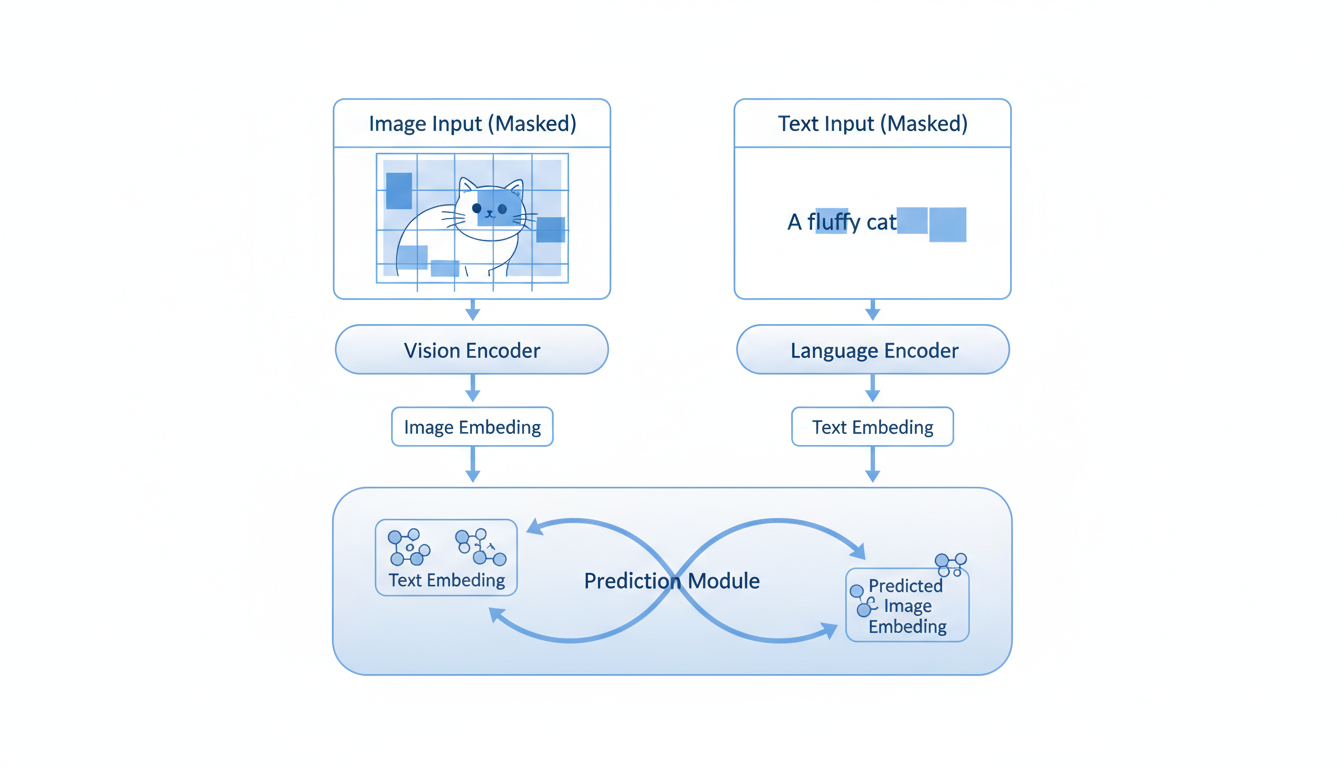
Current Generative World Models try to do the heavy lifting of rendering that video. But there is a new architectural paradigm—spearheaded by researchers at Meta AI and others—called **JEPA (Joint Embedding Predictive Architecture)**. Specifically, we're looking at its application in vision and language, or **VL-JEPA**.
This isn't about creating more content. It’s about creating smarter, more efficient, and more grounded representations of reality. Today, we’re going to walk through why this non-generative approach might actually be the key to the next generation of machine intelligence.
---
The Generative Trap: A Foundation
To understand why VL-JEPA is such a big deal, we first need to look at the current status quo. We need to talk about the "Generative Trap."
The Reconstruction Obsession
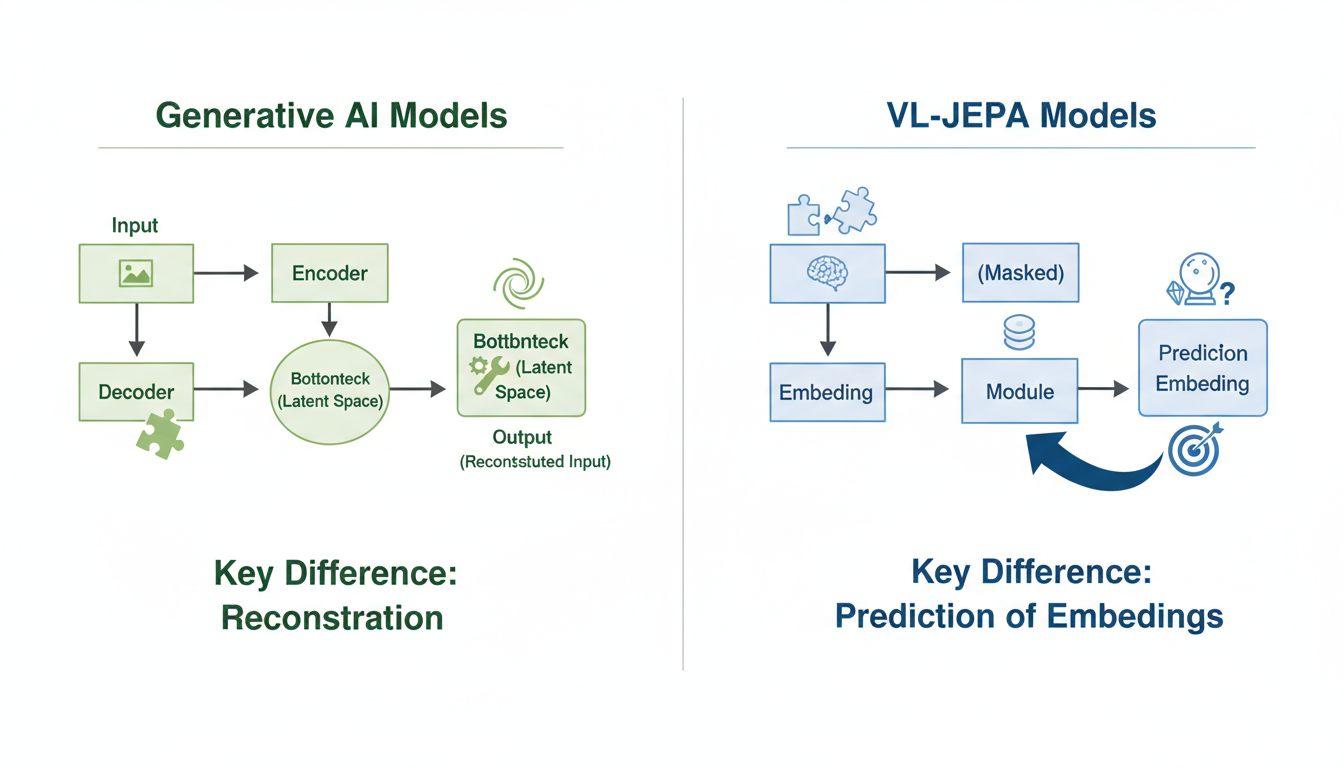
Most of the AI models dominating headlines today—Large Language Models (LLMs) and Generative Image Models—operate on a principle of **reconstruction**.
In the text world, models like GPT are trained to predict the next token. They look at a sequence of words and calculate the probability of what comes next. In the vision world, masked autoencoders or diffusion models often try to reconstruct missing pixels or denoise an image to get back to the original.
According to the research (Sources 3, 4, 5, 6), these generative models are designed to produce new data instances that resemble their training data. They live in the land of high-dimensional output. If you ask a model to predict the next frame of a video, it has to decide the color value of millions of pixels.
The Efficiency Problem
Here is where it gets messy. Predicting every single pixel is incredibly computationally expensive (Source 20). It requires massive resources because the model is sweating the small stuff—the texture of the grass, the slight shift in lighting, the random noise of a camera sensor.
But are those details actually relevant to *intelligence*?
If I show you a picture of a dog running in a park and cover up the dog's leg, your brain knows a leg goes there. You don't need to know the exact arrangement of fur strands to understand the concept "dog leg." Generative models, by forcing themselves to reconstruct the raw data, often waste vast amounts of compute modeling these high-frequency, irrelevant details.
This is where VL-JEPA enters the chat.
---
Enter the JEPA: Understanding Without Creating
**VL-JEPA** (Vision-Language Joint Embedding Predictive Architecture) flips the script. Instead of asking, "What does the missing part look like?" it asks, "What does the missing part *mean*?"
The Core Philosophy
At its heart, JEPA is a **non-generative** framework. As outlined in the key findings (Source 20), it does not generate raw data. It doesn't output pixels. It doesn't output tokens.
Instead, it predicts **abstract embeddings**.
Let’s break that down, because "abstract embedding" is one of those terms that sounds like Star Trek technobabble until you ground it.
Imagine you are watching a movie.
- **Generative Approach:** You try to draw the next scene on a canvas, getting every shadow and color perfect.
- **JEPA Approach:** You write a one-sentence summary of what happens next. "The hero enters the room and finds the treasure."
That summary is the "embedding." It captures the semantic essence—the meaning—of the scene without getting bogged down in the visual noise. JEPA models learn to predict the representation of the missing information rather than the information itself.
Why This Changes Everything
By shifting the target from raw data to embeddings, VL-JEPA achieves three things that are incredibly difficult for generative models:
- **It ignores the noise:** The model learns to filter out unpredictable, high-frequency details (like the rustling of leaves in the wind) because they don't change the semantic meaning of the scene (Source 20).
- **It is computationally efficient:** Predicting a compact vector (a list of numbers representing meaning) is vastly cheaper than generating a 4K image (Source 20).
- **It builds robust representations:** Because the model isn't memorizing surface-level details, it learns features that are more invariant and robust. It understands the "structure" of the data.
---
Under the Hood: How VL-JEPA Works
Alright, let’s put on our engineering hats. How do you actually build a machine that predicts meaning? The architecture is elegant in its specific complexity. Based on the research (Sources 1, 10, 12, 20), here is the blueprint.
The Triad: Context, Target, and Predictor
A JEPA model consists of three main neural networks working in concert:
- **The Context Encoder:** This is the "observer." It takes the visible part of the data (e.g., the unmasked patches of an image or the first few seconds of a video) and converts it into a representation.
- **The Target Encoder:** This is the "truth teller." It looks at the part of the data we want to predict (e.g., the masked patch or the future video frame) and converts it into an embedding. This embedding becomes the ground truth—the goal.
- **The Predictor:** This is the "guesser." It takes the output from the Context Encoder and tries to predict the output of the Target Encoder.
The Self-Supervised Game
The training process is a game of hide-and-seek played in high-dimensional space.
- **Masking:** You take an image or video and hide parts of it.
- **Encoding:** The visible parts go through the Context Encoder. The hidden parts go through the Target Encoder.
- **Prediction:** The Predictor tries to bridge the gap. It tries to guess the vector produced by the Target Encoder using only the information from the Context Encoder.
- **The Loss:** The system calculates the distance between the *predicted embedding* and the *actual target embedding*. It then updates the weights to make that distance smaller next time.
The Secret Sauce: Momentum Updates
There’s a catch here. If you just trained all these networks normally, the model might find a "trivial solution." The Context Encoder and Target Encoder could simply agree to output all zeros. The Predictor would predict zeros, the error would be zero, and the model would learn absolutely nothing.
To prevent this, JEPA uses a **momentum update** (Source 20). The Target Encoder is not trained via gradient descent directly. Instead, its weights are a slowly moving average of the Context Encoder's weights. This forces the Target Encoder to provide a stable, moving target, preventing the system from collapsing into a lazy, constant output. It’s a subtle technical detail, but it’s the difference between a model that learns and a model that naps.
---
V-JEPA: The Killer App is Video
While the architecture works for images (CNN-JEPA) and even 3D point clouds (Point-JEPA), the research suggests that the "killer app" for this technology is video. This is where **V-JEPA** (Video JEPA) comes in (Source 20).
The Difficulty of Video Generation
If generating images is hard, generating video is a nightmare. You have to maintain consistency across time. If a car drives behind a tree, it needs to emerge on the other side looking like the same car. Generative video models often struggle with "flickering" or morphing objects because they are regenerating the object frame by frame.
Predicting Motion and Consequence
V-JEPA bypasses this by treating video as a stream of semantic states. It masks out large chunks of future video frames and asks the model to predict the embedding of those future frames.
This forces the model to learn **world modeling** capabilities. To predict the embedding of a car driving behind a tree, the model must internally understand:
- Object permanence (the car still exists).
- Velocity (how fast it's moving).
- Occlusion (it's hidden but not gone).
According to Meta AI (Source 20), V-JEPA learns these predictive world models entirely from unlabeled video. It doesn't need humans to label "car" or "tree." It learns the physics of the scene simply by trying to predict the semantic outcome of the video stream.
This is a massive step toward what researchers call **Embodied AI** or **Physical Intelligence**. If you want a robot to fold laundry, it doesn't need to be able to paint a picture of a shirt; it needs to predict how the shirt will deform if it pulls on a sleeve. JEPA is the engine for that kind of prediction.
---
Beyond Vision: The Multi-Modal Horizon
While V-JEPA is the star of the show in the current report, the "VL" in VL-JEPA hints at the broader ambition: **Vision-Language**.
Semantic Alignment
The beauty of working in embedding space is that embeddings are a universal language for AI. If you can encode an image of a cat into a vector, and the word "cat" into a similar vector, you have bridged the modalities.
Research indicates that JEPA models are being explored for diverse modalities beyond just video:
- **Audio:** Handling soundscapes (Source 20 mentions diverse modalities).
- **Trajectory Data (T-JEPA):** Predicting the movement paths of objects (Source 9).
- **Reinforcement Learning (RL):** Using JEPA to help agents plan in complex environments (Source 8).
In these scenarios, the JEPA framework serves as a "Foundation Model" recipe. You pre-train on massive amounts of unlabeled data (which is cheap and abundant) to learn the structure of the world, and then you fine-tune on specific tasks with a small amount of labeled data (Sources 1, 2, 11, 14).
The Efficiency Dividend
I want to circle back to efficiency because it cannot be overstated. We are currently hitting a wall where training larger generative models requires nuclear-power-plant levels of energy.
JEPA offers a path to scaling intelligence that doesn't necessarily require scaling compute linearly. By discarding the need to model high-frequency noise, we can train models that are "smarter" per FLOP (floating-point operation) than their generative counterparts. For researchers and companies without the budget of a small nation state, this is a very big deal.
---
The Verdict: A New Paradigm?
So, are we done with Generative AI? Of course not. Generative models are incredible tools for creativity, interface design, and synthetic data creation. They aren't going anywhere.
But VL-JEPA represents a maturation of the field. It acknowledges that **creation** and **comprehension** are different tasks.
If we want AI that can hallucinate a sci-fi novel, we use a Generative Model. If we want AI that can watch a video of a traffic accident, understand who was at fault, and predict what happens next without getting distracted by the reflection on the bumper, we use a JEPA.
The Unanswered Questions
As with any frontier research, there are still unknowns on the horizon.
- **Scalability:** While efficient, we need to see how JEPA architectures scale compared to the massive transformers of the LLM world. Do they keep getting smarter, or do they plateau?
- **Language Complexity:** Can JEPA capture the nuance of complex language reasoning as well as next-token prediction does? The report focuses heavily on vision (V-JEPA), but the "Language" part of VL-JEPA is the next great frontier.
- **The Fine-Tuning Dance:** How easily can these abstract representations be adapted for specific, granular tasks? Abstract is good for general understanding, but sometimes you *do* need the details.
Final Thought
We are moving from an era of AI that is essentially a very talented improvisational artist to an era of AI that is a thoughtful observer. VL-JEPA is the quiet, observant student in the back of the class who isn't saying much, but is understanding everything.
And in the long run, understanding usually wins.
*Sources: This article synthesizes findings from current research reports on VL-JEPA, specifically referencing Meta AI's work on V-JEPA (Source 20), foundational tutorials on JEPA (Sources 1, 10), and applications in 3D and Trajectory modeling (Sources 2, 9).*
---
*I’m Fumi. I read the whitepapers so you don’t have to. If you enjoyed this deep dive into the non-generative side of AI, stick around. We’ve got a lot more ground to cover.*

Source Research Report
This article is based on Fumi's research into VL-JEPA. You can read the full research report for more details, citations, and sources.
📥 Download Research Report (Markdown)